Le C++ est sans conteste l’un des langages les plus complets mais aussi les plus complexes existant dans le monde du développement en entreprise. Ses grandes flexibilité et diversité en font à la fois un langage puissant et dangereux. Il ne s’agit pas ici d’en faire une nouvelle présentation; de nombreux ouvrages lui sont déjà consacrés : qu’il s’agisse des “design patterns” ou de fonctionnalités générales, il y en a vraiment pour tous les goûts.
Cependant, j’ai décidé aujourd’hui de traiter d’un point en particulier, souvent mal perçu par les débutants et parfois même par des gens plus expérimentés : il s’agit de la directive inline.
Piqûre de rappel
Avant d’avancer sur le chemin de “l’inlining”, rappelons quelques principes élémentaires du C++.
Remarque : En tant que programmeur expérimenté, vous connaissez probablement déjà tout ce qui suit. Vous devriez tout de même prendre le temps de lire cette partie pour deux raisons : la première, ça ne fait jamais de mal. Et la deuxième : si jamais j’écrivais une bêtise, vous pourriez gentiment me le faire remarquer ! ![]()
Le C++ est un langage compilé (par opposition à langage interprété), ce qui signifie qu’il induit la génération d’un “binaire” lors d’une phase appelée compilation. Ce binaire peut être un fichier exécutable (.exe sous Windows), une bibliothèque (.so/.a sous Unix, .lib/.dll sous Windows) ou un fichier objet intermédiaire (.o sous Unix, .obj sous Windows).
La phase que l’on nomme “compilation” est en fait séparée en trois étapes successives :
- Le prétraitement (ou “preprocessing”), qui va se charger de remplacer les différentes macros présentes dans le code par leur véritable valeur. Le résultat de ce prétraitement est passé au “compilateur”.
- La compilation, qui transforme le code pré-traité en langage machine au sein de fichiers objets. En pratique, il y a un fichier objet généré par unité de traduction (ou “translation unit”).
- L’édition des liens, qui rassemble les fichiers objets générés au sein d’une seule entité (une bibliothèque dynamique ou un exécutable). Si on a déclaré et utilisé une fonction mais que son implémentation est absente, cette étape ne passe pas.
Remarque : Habituellement, dans le cas d’une bibliothèque statique, l’édition des liens n’est pas effectuée : il s’agit d’une simple concaténation des fichiers objets.
Les bonnes pratiques du C++ dictent ensuite que lorsque l’on écrit le code d’une classe, on place sa définition (et donc sa déclaration) dans un fichier dit “header“, et son implémentation dans un fichier “source“.
Il existe une règle nommée “règle de la définition unique” (ou ODR : “One Definition Rule“) qui dit que l’on peut déclarer autant de fois que l’on veut une classe, une fonction, etc. mais qu’on ne peut la définir qu’une seule fois. Nous verrons plus tard en quoi inline influe à ce niveau.
Un exemple simple
Prenons un exemple tout simple avec une classe “Person” qui représente… une personne. ![]()
Voici le fichier header :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
/** * \file person.hpp * \author Julien Kauffmann * \brief A person. */ #ifndef PERSON_HPP #define PERSON_HPP #include <string> class Person { public: /** * \brief Create a person given its name. * \param name The person name. */ Person(const std::string& name); /** * \brief Get the name. * \return The name. */ const std::string& name() const; private: /** * \brief The name. */ std::string m_name; }; #endif /* PERSON_HPP */ |
Dans ce header, nous avons déclaré et défini le type Person.
Son implémentation, elle, va dans le fichier source :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/** * \file person.cpp * \author Julien Kauffmann * \brief A person. */ #include "person.hpp" Person::Person(const std::string& _name) : m_name(_name) { } const std::string& Person::name() const { return m_name; } |
Si nous reprenons les trois étapes de la compilation, voici ce que se passe pour chacun des fichiers :
Le processus commence par le choix de l’unité de traduction à compiler : ici, il s’agit du fichier “person.cpp”.
- Le préprocesseur analyse chaque ligne, procède à l’inclusion du fichier “person.hpp” (directive #include) tel qu’on le ferait avec un copier-coller. Au passage, tous les commentaires dans les fichiers sont supprimés, et les éventuelles macros sont remplacées.
On se retrouve avec un fichier qui se rapproche théoriquement de ça :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// J'omets volontairement la définition de std::string qui est *un peu* longue ! class Person { public: Person(const std::string& name); const std::string& name() const; private: std::string m_name; }; Person::Person(const std::string& _name) : m_name(_name) { } const std::string& Person::name() const { return m_name; } |
- Le compilateur vérifie la syntaxe de l’ensemble du fichier et compile chaque implémentation de fonction (ou méthode) qu’il rencontre. Ici, les codes du constructeur Person::Person() et du “getter” name() sont effectivement transformés en langage machine au sein d’un fichier objet.
- Enfin, si le programme fait référence à Person::Person() ou Person::name(), l’édition des liens associera l’appel de fonction à son adresse effective.
Les idées fausses sur la directive “inline”
S’en suit ici un florilège des idées reçues que j’ai déjà entendu (ou prononcé :D) ça et là sur inline :
- “Ça sert à ordonner au compilateur de ne jamais compiler le code de la fonction.”
- “C’est quand on écrit directement du code dans la définition d’une classe.”
- “C’est pour accélérer les appels à une fonction.”
- “Ça sert à déclarer des macros intelligentes.”
- “Ça indique que la fonction a une liaison interne.”
En réalité, voici la raison d’être du mot clé inline, telle que définie par Bjarne Stroustrup :
The
inlinespecifier is a hint to the compiler that it should attempt to generate code for a call of the inline function rather than laying down the code for the function once and then calling through the usual function call mechanism.
Pour ceux que l’anglais rebute :
La directive
inlineest une information donnée au compilateur lui indiquant qu’il devrait essayer de générer du code pour chaque appel de la fonction plutôt que de générer une seule fois le code de façon générique et d’utiliser le mécanisme habituel d’appel de fonction.
En gros, on apprend que la directive inline n’est pas un ordre, mais une simple indication, que le compilateur est d’ailleurs libre de refuser. Souvenez-vous que c’est son travail d’optimiser le code généré, pas le vôtre.
En pratique, on utilisera donc pas inline pour des raisons d’optimisation, mais simplement pour modifier la “One Definition Rule”. En effet, là où une fonction ne doit habituellement avoir qu’une seule définition parmi toutes les unités de traductions, le fait de la rendre inline change la règle et indique que la fonction doit avoir la même définition dans chacune des unités de traduction qui l’utilise.
Un exemple
Prenons pour exemple le célèbre cas de la fonction factorielle.
Remarque : Le choix de cet exemple n’est pas innocent. Bjarne Stroustrup utilise lui-même cet exemple lorsqu’il parle de la directive inline.
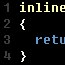
Une implémentation naïve de factorielle est la suivante :
|
1 2 3 4 |
inline int factorial(int n) { return (n < 2) ? 1 : n * factorial(n - 1); } |
Note : Cette fonction n’est pas optimale (on répète inutilement le test “(n <= 1)" à chaque itération. Mais elle convient très bien pour notre exemple.
Supposons que cette fonction est déclarée dans un header de notre bibliothèque et qu’un utilisateur de cette bibliothèque utilise quelque-part dans son code la fonction, par exemple :
|
1 2 3 4 5 6 |
int main() { int f = factorial(6); std::cout << "Factorial(6) = " << f << std::endl; return EXIT_SUCCESS; } |
Lors de la compilation de ce code, il peut se passer plusieurs choses :
- Le compilateur peut décider de compiler la fonction factorial comme n’importe qu’elle autre fonction. Elle aura en pratique un passage de paramètre, une pile d’appel etc.
- Ou il peut décider de remplacer factorial(6) par 6 * factorial(5) directement.
- Enfin, un compilateur très intelligent peut carrément décider “d’inliner” complètement l’appel et de remplacer factorial(6) par 720, optimisant de ce fait drastiquement le programme.
On notera que l’appel d’une fonction inline est sémantiquement identique à celle d’une fonction “classique”. Il est possible d’en hériter, de la surcharger, etc.
Utilisation au quotidien
Voici quelques usages corrects de fonctions “inline” :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
namespace Foo { class Bar { public: int value() const { return m_value; } int add(int a) const; template T sub(T a) { return m_value - a; } private: int m_value; }; inline Bar::add(int a) const { return m_value + a; } } |
- Dans le premier cas, la méthode value() est directement définie au sein de la définition de la classe. Elle est implicitement déclarée inline. L’ajout du mot clé inline serait redondant et donc inutile.
- Dans le second cas, la méthode add() est simplement déclarée (sans mot clé particulier) au sein de la classe. Sa définition est écrite dans le fichier header, en dehors de celle de la classe, mais toujours dans le même namespace, tel qu’on le ferait si on implémentait cette fonction dans le fichier source. Dans ce cas, la définition de la fonction étant écrite au sein même du fichier header (et donc potentiellement présente dans plusieurs unités de traduction), on doit cependant ajouter le mot clé inline pour s’affranchir de la “One Definition Rule“.
- Enfin, dans le dernier cas, la méthode sub n’est pas une vraie méthode mais un template. L’ajout de la directive inline n’est pas obligatoire, car encore une fois, la définition de la méthode se situe dans la définition de la classe. Elle est donc implicitement inline.
N’utilisez inline que sur de très petites fonctions (notion subjective mais en gros : si votre fonction fait plus qu’une simple opération arithmétique ou un retour de valeur, elle n’a surement pas d’intérêt à être inline) et si possible, uniquement sur celles qui ont vocation à être appelées souvent. Les meilleurs candidats pour inline sont généralement bien sûr les getters, les setters, ou encore les destructeurs virtuels vides.
Conclusion
La première fois que l’on m’a parlé du mot clef inline, on me l’a présenté comme un moyen d’optimiser les appels de fonction. Pendant très longtemps, j’ai d’ailleurs soutenu cette version aveuglement. Mais nous avons vu aujourd’hui que les compilateurs sont suffisamment capables pour déterminer d’eux-même quand, quoi et comment optimiser.
En pratique, on retiendra que de bonnes connaissances concernant la “One Definition Rule” et la directive inline sont indispensables à l’écriture d’un code réutilisable et maintenable.
J’espère que cet article vous aura appris quelque-chose (ou à défaut intéressé). N’hésitez pas à me signaler dans les commentaires les éventuelles erreurs que j’aurais pu commettre.
Bon code !
Excellent article,
cependant j’ai encore du mal à comprendre ce qu’est une unité de traduction ?
Merci beaucoup !
Une unité de traduction (ou “translation unit”) c’est le fichier intermédiaire généré après le passage du préprocesseur : un gros fichier plat avec tous les #include inclus et les commentaires supprimés.
En général, on a une “translation unit” par fichier .cpp compilé.
Est-ce que ça t’aide ?!
Oui merci.
Et n’hésite pas à faire des articles sur le C++ :p
Je me ferais une joie de les lire et d’y apprendre des nouveaux concepts
Excellent article. Je ne savais pas que les fonctions définies dans le corps de la classe étaient automatiquement indiquées inline. Merci.
Je ne savais pas que les fonctions définies dans le corps de la classe étaient automatiquement indiquées inline. Merci.
Ping : Tweets that mention « La directive « inline » demystifiée -- Topsy.com
Très intéressant en effet, j’avais la mauvaise habitude d’inliner trop souvent, mais pas forcément quand il le fallait…
Merci pour l’article
Ravi d’avoir pu aider !