J’ai commencé à entendre parler de Git il y a quelques temps déjà mais je n’avais jamais eu l’occasion de vraiment travailler avec. Pour moi, son seul intérêt était qu’il était distribué, mais sans comprendre exactement ce que ça impliquait. Aujourd’hui les choses ont changé et j’ai, pour mon plus grand bonheur découvert un outil incroyablement puissant et efficace. À mon sens, git n’est pas simplement un autre gestionnaire de sources, c’est une nouvelle façon de penser le développement. Dans cet article, nous allons brièvement présenter Git en comparaison avec d’autres gestionnaires de sources plus “classiques” puis expliquer son installation sous Windows.
Présentation
Il existe de très nombreuses ressources sur l’Internet (mais pas que) qui présentent Git de façon très complète. L’objectif de cet article n’est pas de faire de vous un expert Git en quelques pages mais simplement de vous présenter l’outil et de, j’espère, vous donner l’envie de l’utiliser. si vous connaissez déjà suffisamment Git, vous pouvez sauter la section suivante et directement vous rendre à la partie “Installation sous Windows”.
Un gestionnaire de sources
Git est un gestionnaire de sources, comme Subversion (SVN), CVS ou encore Visual Source Safe (VSS). Un outil qui assure principalement les rôles suivants :
- Il permet de stocker différentes versions du code source.
- Il permet un travail collaboratif en facilitant la synchronisation entre différents développeurs.
- Il permet de savoir qui est à l’origine d’une modification
Les trois derniers outils que j’ai cités ont en commun leur architecture centralisée : tous les développeurs synchronisent leurs fichiers de code source auprès d’un dépôt central. Cette approche, très simple à comprendre est souvent plébiscitée par les entreprises, pour différentes raisons :
- L’administration d’un dépôt central est plutôt simple : on peut régler finement et individuellement les droits d’accès.
- Tout le monde comprend la notion de “publier” ses sources dans un dépôt central.
- En entreprise, en général, les liaisons réseaux sont fiables et robustes; l’accès 24H/24 au dépôt est quasi-garanti.
- Les clients ne disposent que du code source sur lequel ils travaillent actuellement; l’historique reste, lui, dans le dépôt.
Git se distingue principalement par son architecture distribuée. Avec Git, il n’y a pas de dépôt central, principal, ou autre : chaque dépôt Git contient tout l’historique du dépôt, de façon autonome. Il n’y a pas d’entité supérieure. Les dépôts peuvent communiquer entre eux selon des règles très simples. Ses avantages principaux sont les suivants :
- Le dépôt, puisque local et autonome, est toujours accessible et extrêmement rapide, même lorsque déconnecté du réseau.
- Git ne stocke pas les fichiers, mais les différences entre les fichiers : ce principe lui permet de disposer d’un des mécanismes de fusion (ou “merge”) les plus efficaces.
- Contrôle total sur le dépôt : on ne dépend plus d’une entité externe. Avec une solution centralisée, si le dépôt nous lâche, adieu l’historique.
- Un système de branchage extrêmement efficace.
Note : Il n’y aucun mal à utiliser un gestionnaire de sources centralisé; c’est d’ailleurs dans bien des cas la solution la plus adaptée. Cependant, puisque cet article parle essentiellement de Git, nous allons nous concentrer sur des cas où l’utilisation de Git semble plus opportune. Vous trouverez ici un historique plus précis de git et des raisons de sa création.
Avant de commencer
Si vous êtes déjà habité à utiliser un gestionnaire de sources “classique”, avant de continuer prenez quelques minutes pour vous rappeler de leur fonctionnement puis oubliez tout ! En tout cas temporairement : l’utilisation de Git est drastiquement différente et lui appliquer la logique d’un gestionnaire de source centralisé n’aurait aucun sens. Pour ma part, je suis habitué à utiliser SVN et il m’a fallu une certaine période d’adaptation pour comprendre que son fonctionnement était plus différent qu’il n’y paraissait.
Note : Bien que différents, il est tout à fait possible d’utiliser un dépôt SVN avec la ligne de commande git, grace à “git svn” qui s’avère être un moyen très simple de découvrir git sans changer ses dépôts existants. Je l’utilise depuis plusieurs semaines maintenant et j’en suis vraiment très satisfait.
Concepts
Chaque dépôt Git conserve un historique de tous les changements (ou “commits”) depuis sa création, potentiellement au sein de plusieurs branches. Au sein d’un dépôt, on ne peut travailler à la fois que dans une seule branche et sur un seul commit. Lorsqu’on a effectué des changements au sein d’une branche, on peut librement les enregistrer à la suite de la branche (on parle de faire un “commit”) et continuer (éventuellement en allant travailler dans une autre branche). Il est par la suite possible de fusionner (faire un “merge”) de plusieurs branches pour répercuter les changements de l’une dans l’autre. La philosophie de Git, c’est de faire des commits très souvent, même (et surtout) pour de petites modifications. Plus vous “commiterez” souvent, plus il sera facile pour Git de fusionner vos changements avec ceux des autres.
Installation sous Windows
J’ai longtemps travaillé avec Subversion (SVN) sous Windows en utilisant TortoiseSVN. Cet outil graphique est plutôt bien pensé et m’a toujours satisfait. En voulant essayer git, je me suis donc naturellement porté vers TortoiseGIT mais je dois avouer que j’ai été déçu. Je pense que les gens derrière TortoiseGIT ont fait un travail remarquable et ils continuent d’améliorer le logiciel, mais à l’heure actuelle l’outil me paraît plus contraignant à utiliser que sa version classique en ligne de commande (comme sous Linux). C’est donc sur cette dernière que va porter l’installation.
Téléchargements
Commencez par télécharger git en vous rendant sur cette page. Prenez la dernière version existante de git (Version “Git-1.7.3.1-preview20101002.exe” à l’heure actuelle). Exécutez l’installation :

Installation de git
Choisissez les modules que vous souhaitez installer. Pour ma part, j’ai choisi ces modules :

Modules à installer
Enfin, l’installeur vous demande de quelle façon vous souhaitez installer git. Les deux premières options nécessitent l’utilisation d’une console de type UNIX (msys/cygwin) pour l’utilisation de Git, la dernière permet d’utiliser git depuis une console native (type “cmd.exe” ou encore Powershell).

Mode d'installation de git
C’est cette dernière option que nous choisirons pour les raisons suivantes :
- La console UNIX est vraiment très puissante et efficace… mais, à mon sens, assez peu adaptée à Windows.
- De nombreux développeurs Windows utilisent déjà Powershell et donc il faut pouvoir utiliser git depuis n’importe quelle console. Changer de console juste pour commit ses changements dans git n’est pas envisageable.
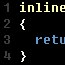
Notez que comme il est indiqué dans l’installeur, la dernière option va remplacer une partie des outils Windows (tels que find.exe et sort.exe) par leur équivalent GNU. Si vous utilisez ces outils, vous pourrez toujours les utiliser, mais il faudra les préfixer par leur chemin complet. Une fois l’installation terminée, lancez une console puis saisissez la commande :
|
1 |
git --version |
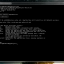
Si vous obtenez la sortie suivante :

Obtenir la version installée de git
C’est que git est correctement installé et fonctionnel. Félicitations !
Configuration préliminaire
Il est possible de configurer un bon nombre de choses dans git. Cela passe du nom d’utilisateur au proxy à utiliser ou à l’activation des couleurs lors de l’affichage des informations du dépôt. Les configurations de git sont soit globales, soit propres à chaque dépôt. En pratique, si une valeur de paramètre n’est pas trouvée au sein du dépôt, git va regarder la configuration globale. Voici les paramètres les plus couramment modifiés :
|
1 2 3 4 5 6 |
git config --global user.name "Votre nom" git config --global user.email "adresse@email.com" git config --global color.branch auto git config --global color.diff auto git config --global color.interactive auto git config --global color.status auto |
Le deux premiers sont assez explicites; les quatre suivant activent les couleurs lors des commandes associées (ce qui est quand même plus sympathique). Il existe évidemment encore bien d’autres paramètres, je vous invite à consulter la page de manuel de git-config pour les découvrir.
Utilisation basique
Le moyen le plus efficace, c’est de pratiquer. Commençons par créer un dépôt git :

Création d'un dépôt git
Note : Plutôt que de créer un dépôt vide, on aurait également pu choisir de cloner un dépôt existant avec la commande “git clone”.
Créons un fichier à ajouter au dépôt :

Création d'un fichier à ajouter au dépôt
La commande “git status” permet d’interroger le dépôt sur le statut actuel de la copie de travail (ou “working copy”). Ici, on voit que le fichier main.cpp a été créé mais n’est pas suivi (ou “tracked”) par le dépôt. Indiquons à git que ce fichier doit être suivi et faire partie du prochain commit :

Ajout d'un fichier au dépôt
Pour ce faire, nous avons utilisé la commande “git add” qui permet d’indiquer qu’un fichier (même si il est déjà suivi) doit faire partie du prochain commit.
Après “git add”, “git status” nous indique bel est bien que le fichier doit être suivi. Nous pourrions à ce moment là, ajouter d’autres fichiers, en modifier, voire en supprimer ou en déplacer certains. Il faut simplement signaler à git que le changement (quel que soit sa nature) doit faire partie du prochain commit.
Nous nous contentons de ce simple ajout pour l’instant.

Historisation d'un changement
La commande “git commit” permet de sauver le changement au sein du dépôt. Ici le paramètre “-m” permet de spécifier un message à associer au commit. Sans ça, git aurait ouvert un éditeur de texte pour nous demander de saisir notre message.
Note : La saisie d’un message est extrêmement importante. Les messages ne doivent pas forcément être très longs, mais il ne devraient jamais être vides. À quoi sert-il de mettre ses changements sous historiques si on est incapable de dire pourquoi ils ont été faits ? Même lorsque vous travaillez seul, prenez l’habitude de toujours renseigner des messages informatifs pour chacun de vos commits. C’est une habitude que vous ne regrettez pas.
Après le commit, on constate que la “working copy” a été mise à zéro : “git status” indique qu’aucun changement n’a été apporté depuis le commit actuel. Nous pouvons bien entendu dès à présent consulter l’historique de notre dépôt grâce à la commande “git log” :

Consultation de l'historique
Le commit est bien dans l’historique. Il s’est vu assigner un identifiant unique “c0d281e3532a4970415bba1e9159b1dc7ed816b1″. Modifions maintenant le fichier main.cpp, de la façon suivante :

Le fichier main.cpp modifié
Après sauvegarde des modifications, on utilise “git status” qui nous informe qu’en effet, main.cpp a été modifié par rapport à la version actuelle :

Le fichier main.cpp a été modifié
Notons que bien que modifié, le fichier n’est pas automatiquement marqué comme faisant partie du prochain commit.
Nous pouvons afficher la liste des modifications apportées au fichier grâce à la commande “git diff” :

Utilisation de git diff pour lister les changements
Nous souhaitons archiver cette nouvelle version de main.cpp. Pour ce faire, nous pouvons faire “git add main.cpp” suivi de “git commit” ou bien directement :

Archivage de la correction de main.cpp
L’argument “-a” permet de dire à “git commit” qu’il doit automatiquement ajouter tous les fichiers déjà suivis qui ont été modifiés depuis le dernier commit.
Encore une fois, un appel “git log” nous donne la sortie suivante :

Affichage des logs du dépôt
Le changement a bien été archivé. Il est possible de revenir à un état antérieur du dépôt grâce à la commande “git checkout” :

Utilisation de git checkout
Et bien entendu de revenir à la dernière version en date en utilisant : “git checkout master”, où “master” est le nom de la branche à utiliser. Note : par défaut, la branche principale d’un dépôt git est nommée “master”. Il s’agit d’une convention, que vous êtes libre de ne pas suivre, mais qu’il est tout de même recommandé de respecter.
Aller plus loin
Nous n’avons vu ici qu’un petit aperçu de l’utilisation et du principe de git : il y a bien plus à voir et à découvrir. Il est également possible de (liste loin d’être exhaustive) :
- Partager ses modifications avec un ou plusieurs autres dépôts (“push”, “pull”, “fetch”, etc.).
- Effacer localement certains commit intermédiaires ou de réécrire totalement l’historique (lorsque cela est absolument nécessaire).
- Utiliser git avec un dépôt SVN (“git svn”) pour par exemple faciliter la transition.
- Rechercher quelle modification a introduit un bogue (“git bissect”)
Pour tout découvrir, je vous recommande notamment le livre Pragmatic Guide to Git qui est à la fois très facile d’accès et très complet. N’hésitez pas non plus à consulter les pages de manuel de git qui sont très bien fournies. Comme toujours, n’hésitez pas à poser vos questions si j’ai manqué de clarté sur certains aspects.









 “C:\android-sdk-windows\tools” à mon PATH :
“C:\android-sdk-windows\tools” à mon PATH :




