Nombreux sont les programmeurs C++ qui ont d’abord été confrontés au C. Les deux langages partagent en effet bien des fonctionnalités… mais ont également de grandes différences.
Parmi ces différences, on trouve les opérateurs de conversion C++. Ils sont certainement l’un des points les plus mal compris par les développeurs C qui voient souvent en eux un verbiage inutile. L’objectif de cet article est de (dé)montrer l’utilité des opérateurs de conversion C++, en comparaison avec les conversions classiques, dites : “à la C” et de comprendre ce qu’ils peuvent apporter au programmeur en termes de maintenabilité et de sécurité.
Un petit mot sur les conversions
Les conversions (ou “cast” en anglais) sont un des outils incontournables du programmeur C++. Mais comme tout outil, il faut savoir les utiliser à bon escient.
Dans l’idéal, un programme doit contenir le moins possible de “casts” : les types doivent s’interfacer naturellement les uns avec les autres. Cela garantit un découplage du code et donc une meilleure maintenabilité. Cela ne signifie pas qu’il faille à tout prix éviter les “casts” mais simplement qu’il faut les utiliser avec parcimonie.
Dans les sections qui suivent, nous allons expliquer le rôle de chaque opérateur de conversion. Pour l’ensemble des sections, nous considérerons les classes suivantes lorsqu’il sera question de hiérarchie :
|
1 2 3 |
class Base { public: virtual ~Base() {} }; class Derived : public Base {}; class Derived2 : public Base {}; |
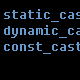
static_cast<>
Il permet plusieurs choses :
- Expliciter les conversions implicites, supprimant du même fait tout avertissement que donnerait le compilateur si la conversion peut entraîner un risque. Exemple : double vers int.
- Convertir vers et depuis n’importe quel type pointé à partir d’un void*. Exemple : void* vers unsigned char*.
- Convertir au travers d’une hiérarchie de classe, sans effectuer de vérification préalable. Exemple : Base* vers Derived* ou Base& vers Derived&.
- Ajouter l’attribut constant au type converti. Exemple : char* vers const char*.
Dans le dernier cas, notez que puisqu’il n’y a aucune vérification et que static_cast<> n’échoue jamais, le code suivant a un comportement indéfini (communément nommé en anglais “undefined behavior” ou “UB“) :
|
1 2 3 4 5 6 7 8 9 10 11 |
void foo() { Base* base = new Derived(); // Ce code est valide et correct car base pointe en fait vers une instance de Derived. Derived* derived = static_cast<Derived*>(base); // Ce code compile mais à un comportement indéfini (Undefined Behavior) // car base ne pointe pas vers une instance de Derived2. Derived2* derived2 = static_cast<Derived2*>(base); } |
Notez que la notion de comportement indéfini n’offre par définition aucune garantie : le code peut avoir le comportement espéré, faire crasher le programme ou provoquer l’envoi d’un missile nucléaire sur Cuba.
Il ne permet pas de :
- Convertir vers ou depuis un type pointé à partir d’un autre type pointé autre que void*. Exemple : unsigned char* vers char*.
- Tester qu’une instance est celle d’un type dérivé. Exemple : tester qu’un Base* est en fait un Derived*.
- Supprimer l’attribut constant du type converti. Exemple : const char* vers char*.
En bref
static_cast<> est sans doute l’opérateur de conversion que vous serez amené à utiliser le plus. Il ne permet que de réaliser des conversions sûres et à pour rôle principal celui d’expliciter les conversions implicites.
Dans le cas du polymorphisme, il est à préférer à dynamic_cast<> lorsque l’on a la garantie que la conversion va réussir.
dynamic_cast<>
Le seul rôle de dynamic_cast<> est de tester à l’exécution si un pointeur d’un type de base est en fait un pointeur vers un type dérivé.
Exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
void foo() { Base* base = new Derived(); // Après l'appel, derived pointe vers l'instance de Derived // car base pointe en fait vers une instance de Derived. Derived* derived = dynamic_cast<Derived*>(base); // Après l'appel, derived2 vaut 0 // car base ne pointe pas vers une instance de Derived2. Derived2* derived2 = dynamic_cast<Derived2*>(base); // Dans le cas d'une référence, si le cast n'est pas possible // Une exception de type std::bad_alloc est lancée. Derived2& derived2_bis = dynamic_cast<Derived2&>(*base); } |
Note : pour que dynamic_cast<> fonctionne, le type de base doit posséder au moins une méthode virtuelle.
Un appel à dynamic_cast<> est plus coûteux qu’un appel à static_cast<>car dynamic_cast<> effectue une recherche dans la “v-table” de l’instance à l’exécution pour déterminer son type exact.
On veillera donc à n’utiliser dynamic_cast<> que lorsqu’il n’y a aucune autre solution.
En bref
dynamic_cast<> est le seul opérateur de conversion à avoir un effet “indéterminé” jusqu’à l’exécution. Son utilisation n’a de sens que lorsque confronté à du polymorphisme. Dans les cas où la conversion est assurée de réussir, on lui préfèrera static_cast<> plus rapide et ne nécessitant pas que les classes possèdent une méthode virtuelle.
const_cast<>
const_cast<> permet de supprimer l’attribut constant ou volatile d’une référence ou d’un type pointé. Exemple : const char* vers char* ou volatile int vers int.
C’est notamment le seul opérateur de conversion à pouvoir le faire : même reinterpret_cast<> n’a pas ce pouvoir.
|
1 2 3 4 5 6 7 8 9 10 11 |
void foo() { char* buf = new char[16]; // L'ajout de l'attribut const ne nécessite pas de cast // Il est implicite const char* cbuf = buf; // Le retrait de l'attribut const nécessite const_cast<>. char* buf2 = const_cast<char*>(cbuf); } |
L’importance d’écrire un code “const-correct”
Directement relié aux opérateurs de conversion, l’écriture d’un code const-correct est un autre aspect du C++ souvent mal perçu par les programmeurs C. Le C est plus ancien et le mot clé const n’y a pas toujours existé; il a été emprunté au C++ par la suite.
Le fait d’indiquer qu’une variable est constante est un outil puissant permettant au compilateur de nous signaler certaines de nos erreurs qui auraient autrement passé la barrière de la compilation.
Qui ne s’est jamais trompé dans l’ordre des arguments d’un memcpy() ?
|
1 2 3 4 5 6 7 8 9 10 |
void foo() { const char* source = "blog.freelan.org"; char* destination = new char[16]; // Oups ! Je me suis trompé dans l'ordre des arguments... // ... heureusement, puisque memcpy spécifie que le premier paramètre est un void* // et pas un const void*, le compilateur m'indique une erreur. memcpy(source, destination, strnlen(source)); } |
Les mots clé “const” ou “volatile” appliqués aux classes
En C++, les mots clé const et volatile s’appliquent évidemment aussi aux instances de classes mais ont des sémantiques différentes :
Le caractère const ou volatile s’applique récursivement aux membres de l’instance.
Il n’est possible d’appeler une méthode d’une classe que dans les cas suivants :
- l’instance n’est pas const.
- l’instance est const et la méthode est déclarée const.
- l’instance est déclarée volatile et la méthode est déclarée volatile.
- l’instance est déclarée const et volatile et la méthode est elle aussi déclarée const et volatile.
À propos de “volatile”
Certains lecteurs peuvent être perdus à la lecture du mot clé volatile qui, il faut bien l’avouer, n’est pas utilisé très souvent. Décrire précisément le rôle de volatile mériterait un article bien à part mais je vais tout de même dire en deux mots à quoi il sert :
Lorsqu’une variable est déclarée volatile, le compilateur n’a pas le droit d’optimiser sa valeur (mise en cache processeur) lors de tests.
Ainsi sans volatile sur la variable do_loop, le code suivant :
|
1 2 3 4 5 |
void foo() { bool do_loop = true; while (do_loop) { doSomething(); } } |
Risquerait d’être optimisé en tant que :
|
1 2 3 4 |
void foo() { while (true) { doSomething(); } } |
Ce qui est correct dans la plupart des cas… sauf si do_loop peut être modifié par un autre thread. C’est principalement dans ce genre de cas que volatile trouve son utilité.
Erreurs courantes
Une erreur courante concernant const_cast<> consiste à supposer que l’on peut toujours supprimer le caractère constant d’une variable.
Ceci est évidemment faux : on ne peut supprimer le caractère constant (respectivement volatile) d’une variable que lorsque celle-ci a été déclarée non-const (respectivement non-volatile).
Ainsi le code suivant a un comportement indéfini :
|
1 2 3 4 5 6 7 8 |
void foo() { const char* cbuf = "blog.freelan.org"; // L'utilisation de const_cast<> ici a un comportement indéfini (undefined behavior) // car cbuf a été déclaré const. char* buf = const_cast<char*>(cbuf); } |
Un autre cas courant est celui des variables membres qui servent à mettre en cache un résultat :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class MyClass { public: MyClass() : m_value_cache(0) {} int getValue() const { if (m_value_cache == 0) const_cast<int&>(m_value_cache) = computeValue(); return m_value_cache; } private: static int computeValue(); int m_value_cache; }; |
L’utilisation de const_cast<> ici est erronée : si on déclare une instance const de MyClass, m_value_cache est aussi const lors de sa définition. L’utilisation de const_cast<> est la même que dans l’exemple précédent et a comportement indéfini.
La bonne solution est d’utiliser le mot clé mutable, qui permet à une variable membre de ne pas avoir les mêmes contraintes const/volatile que son instance parente :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class MyClass { public: MyClass() : m_value_cache(0) {} int getValue() const { // m_value_cache est déclaré mutable // il peut donc changer, même dans une méthode const if (m_value_cache == 0) m_value_cache = computeValue(); return m_value_cache; } private: static int computeValue(); // Utilisation du mot clé "mutable" mutable int m_value_cache; }; |
En bref
const_cast<> est le seul opérateur de conversion à pouvoir supprimer le caractère const ou volatile d’une variable. L’utilisation de const_cast<> doit rester très rare : le contraire indique souvent une importante erreur de design. Son seul usage habituellement toléré est l’interfaçage avec des bibliothèques historiques qui ne sont pas const-correct.
reinterpret_cast<>
Il s’agit de l’opérateur de conversion le plus dangereux, et du plus mal utilisé. Son rôle est de dire au compilateur : “réinterprète-moi la représentation binaire de ce type en tant qu’un autre type”.
Il permet :
- De convertir n’importe quel type pointé en une autre, même lorsque ceux-ci n’ont aucun rapport. Exemple : int* vers double*.
- De convertir un type pointé en sa représentation intégrale et vice et versa. Exemple : int* vers int.
Il est à noter que ces conversions sont dépendantes de l’implémentation. En d’autres termes, le compilateur est libre de faire ce qu’il veut concernant la conversion basée sur reinterpret_cast<> mais ce comportement doit être constant : il ne s’agit pas de comportement indéfini; le comportement est bien défini, simplement pas par le standard C++ mais votre version du compilateur. Si vous vous basez sur cette dépendance de l’implémentation, votre code est donc non-portable.
La seule garantie délivrée par le standard C++ concernant reinterpret_cast<> est que si vous convertissez un type A en un type B, puis de nouveau en un type A, le comportement est bien défini et vous récupérez bien la valeur de départ.
On comprend dès lors facilement le danger que peut représenter reinterpret_cast<>.
Voici un exemple d’utilisation :
|
1 2 3 4 5 6 7 8 9 10 11 |
void foo() { int a = 5; // Le contenu de b dépend du compilateur utilisé // et n'est pas défini par le standard double* b = reinterpret_cast<double*>(&a); // Ici, on a la garantie que *c vaudra a, c'est à dire 5. int* c = reinterpret_cast<int*>(b); } |
Cas particuliers
Le peu de garanties associées à reinterpret_cast<> rendent celui-ci quasiment inutile dans la plupart des cas. Il y a cependant certaines exceptions de fait qui justifient une utilisation de reinterpret_cast<> sans nuire à la portabilité :
Les conversions entre les types char* et unsigned char* bien que non spécifiées par le standard, sont en pratique supportées par tous les compilateurs et produisent le comportement attendu. Le compilateurs ont par ailleurs de plus fortes contraintes à leur égard (spécifiquement au niveau de leur représentation) pour des raisons de compatibilité ascendante avec le C.
Vous pouvez donc clairement supposer qu’un reinterpret_cast<> entre un char* et un unsigned char* sera à la fois portable et défini.
Polymorphisme
reinterpret_cast<> utilisé dans le cadre d’une conversion faisant intervenir du polymorphisme a un comportement non défini. Il n’est ainsi pas correct d’effectuer un reinterpret_cast<> entre par exemple un Base* et un Derived*.
En bref
reinterpret_cast<> est l’opérateur de conversion le plus dangereux : permettant de faire ce qu’aucun autre ne peut faire (des conversions entres des types non liés) il convient de l’utiliser avec la plus grande prudence. En pratique, on lui préfèrera static_cast<> qui permet d’effectuer des conversions plus sûres, y compris vers et depuis des types pointés génériques (void*). Son seul usage toléré est l’interfaçage avec du code C ancien qui utilise pour ses paramètres de “buffer” des char* ou unsigned char* au lieu des void*.
Old-school : les conversions “à la C”
Le C++ supporte toujours l’ancienne syntaxe concernant les conversions “à la façon C”. Cependant, le standard précise clairement l’effet d’une telle conversion :
Le “cast” suivant : (Type)valeur ou Type(valeur)
Sera équivalent à, par ordre de préférence :
- un const_cast<>
- un static_cast<>
- un static_cast<> suivi d’un const_cast<>
- un reinterpret_cast<>
- un reinterpret_cast<> suivi d’un const_cast<>
Les bonnes pratiques indiquent souvent que l’utilisation de ce type de conversion est à bannir, principalement parce qu’il peut résulter silencieusement en un reinterpret_cast<>, qui comme nous l’avons vu, peut se révéler extrêmement dangereux. De plus, l’usage des alternatives modernes aux opérateurs de conversion permet de spécifier clairement l’intention du programmeur et de protéger contre les erreurs involontaires (comme celles que nous avons vu avec const_cast<>).
Une autre utilité
Les “casts” à la C offrent également une possibilité qui n’est permise par aucun autre opérateur de conversion : celle de convertir vers une classe de base au travers d’un héritage privé. Ce type d’héritage est très souvent critiqué et fortement déconseillé. Je ne détaillerai pas ici les conséquences et les raisons de ce type d’héritage; c’est un sujet qui mérite son propre article.
Conclusion
Il y a beaucoup à dire sur les opérateurs de conversion et encore plus à apprendre. Nous avons vu que bien utilisés, ils sont un outil puissant et un allié du programmeur. Protégeant contre les erreurs involontaires et révélant les erreurs de conception, ils restent pour certains dangereux et sont tout de même à utiliser avec la plus grande précaution.
Une bonne connaissance de ces opérateurs de conversion et de leurs limites reste indispensable à la réalisation de programmes maintenables en C++.
Références
Voici une série de liens (en anglais, pour la plupart) qui m’ont inspiré dans la rédaction de cet article.
- http://stackoverflow.com/questions/28002/regular-cast-vs-static-cast-vs-dynamic-cast
- http://stackoverflow.com/questions/332030/when-should-static-cast-dynamic-cast-and-reinterpret-cast-be-used
- http://stackoverflow.com/questions/4708444/is-there-a-good-way-to-convert-from-unsigned-char-to-char
- http://msdn.microsoft.com/en-us/library/5f6c9f8h%28v=VS.80%29.aspx
N’hésitez pas à les consulter pour obtenir d’autres informations. Je vous recommande également de vous inscrire sur Stack Overflow qui est à mon sens le meilleur site de questions/réponses concernant la programmation : le niveau des questions et surtout des réponses y est vraiment très élevé.
Comme toujours bien sûr, vous pouvez également utiliser les commentaires pour obtenir des précisions sur un point ou l’autre.
Merci pour votre lecture !