Tous les langages modernes offrent aujourd’hui, par leur nature orientée objet, un moyen puissant de concevoir des hiérarchies : l’héritage. La plupart des programmeurs sont bien entendu déjà familiers avec le principe de dériver d’une classe pour en étendre les possibilités (ou les restreindre) dans une classe fille. Cependant, dans ce domaine, C++ va un peu plus loin que les autres langages en proposant différentes notions d’héritage public, privé, protégé et virtuel. Nous allons tenter, dans cet article, d’expliquer en détails leurs rôles et en quoi elles peuvent se rendre utiles.
Un cas classique
|
|
class Base { public: int x() const { return m_x; } protected: void set_x(int value) { m_x = value; } private: int m_x; }; class Derived : public Base { public: void foo() { set_x(5); } }; |
Ce code n’évoque probablement rien de nouveau pour la plupart d’entre vous : nous déclarons une classe Base, qui possède une méthode publique, une méthode protégée et une variable membre privée. Nous déclarons également une classe Derived, qui dérive de Base au travers d’un héritage public. Ce principe d’héritage public est généralement simple à comprendre et il est présent dans pratiquement tous les langages objets : lorsque Derived dérive de Base au travers d’un héritage public, on dit aussi que Derived “est un” Base. Toute instance de Derived peut être considérée comme une instance de Base. Comme nous l’avions vu, dans un article précédent, il est également possible de tester si une instance de Base est une instance de Derived grâce à un dynamic_cast<>. De façon résumée, un héritage publique offre les garanties suivantes :
- Toutes les membres (variables et méthodes) publics dans la classe de base le sont aussi dans la classe dérivée.
- Toutes les membres protégés dans la classe de base le sont aussi dans la classe dérivée.
- Les membres privés de la classe de base ne sont pas accessibles à la classe dérivée.
- On peut convertir implicitement un pointeur (respectivement une référence) sur la classe dérivée vers un pointeur (respectivement une référence) sur la classe de base.
- On peut convertir explicitement un pointeur (respectivement une référence) sur la classe de base vers un pointeur (respectivement une référence) sur la classe dérivée.
Ainsi dans notre exemple, Derived peut, dans sa méthode foo() (et indépendamment de la visibilité de cette méthode), appeler la méthode protégée de son parent, set_x(). Elle ne peut pas en revanche, directement accéder à m_x qui est dans une section privée de la classe de base.
Le rôle de l’héritage public
Une concept erroné va généralement de pair avec l’utilisation de l’héritage public : il consiste à dire que ce type d’héritage est utilisé principalement pour favoriser la réutilisation de code. Ceci n’est pas (ou ne devrait pas) être la raison : en C++, il existe beaucoup de moyens de réutiliser son code, la façon la plus efficace étant la composition. Le fait de d’utiliser un héritage public doit être une décision fonctionnelle, et pas une décision technique : ainsi, la classe Table dérive de la classe Meuble parce qu’une table “est un” meuble, et pas parce qu’en faisant ainsi on évite de retaper du code. L’héritage (public ou non) s’il apporte quelque-chose, c’est principalement de la flexibilité.
Bonnes pratiques
Certains auront peut être pensé la chose suivante : “La méthode set_x() ne sert à rien. Autant déclarer m_x protégé directement : il y aura moins de code”. Si cette remarque part surement d’une bonne intention (après tout, avoir moins de code est en général une très bonne idée), elle risque ici d’avoir des conséquences fâcheuses : En procédant de la même façon que dans l’exemple, nous ajoutons certes une méthode, mais nous réduisons également le couplage. En optant pour la solution “simplifiée”, si pour une raison ou pour un autre, je suis amené à modifier l’implémentation de Base et à renommer par exemple m_x en m_first_x, je devrais alors modifier non seulement tout le code de Base mais aussi tout le code de Derived (puisque nous y faisons référence à m_x directement). Le fait d’ajouter une méthode protégée à Base permet de figer son interface “publique” et réduit donc drastiquement le couplage. Il en résulte un code bien plus maintenable. En règle générale, on retiendra que les variables au sein d’une classe seront toujours soit publiques, soit privées, mais très rarement protégées. Et si dans un cas particulier vous sentez avoir vraiment besoin d’un accès à un membre privé, préférez la directive friend qui augmentera bien moins le couplage.
Cette règle n’est évidemment pas absolue et vous risquez de rencontrer un scénario où déclarer une variable membre protégée est la bonne chose à faire. Cependant, ça ne devrait logiquement pas être votre premier réflexe.
L’héritage privé : une alternative à la composition
Qui n’a jamais écrit par erreur, au cours d’une soirée (nuit ?) un peu trop longue quelque-chose de ce genre :
Il en résulte en général de longues minutes très agaçantes où l’on tente de comprendre pourquoi le compilateur refuse systématiquement d’utiliser les variables de la classe parente. La raison est plutôt simple : en l’absence d’un attribut de visibilité, l’héritage par défaut en C++ est privé. Le code précédent est donc équivalent à :
|
|
class Derived : private Base { }; |
Voilà une bonne occasion d’expliquer à quoi sert ce type d’héritage. L’héritage privé offre les garanties suivantes :
- Tous les membres publics dans la classe de base sont privés dans la classe dérivée.
- Tous les membres protégés dans la classe de base sont privés dans la classe dérivée.
- Les membres privés de la classe de base ne sont pas accessibles à la classe dérivée.
- La classe dérivée peut redéfinir les méthodes virtuelles de la classe de base.
- Toutes les méthodes de la classe dérivée peuvent convertir un pointeur (respectivement une référence) sur
Derived en pointeur (respectivement une référence) sur Base. Ceci n’est en revanche normalement pas possible en dehors de la classe dérivée. (Voir tout de même la remarque).
Là où un héritage public traduit une relation de type “est un”, un héritage privé lui traduit une relation de type “est implémenté en tant que”. En pratique, un héritage privé est comparable à une composition de type 1-vers-1. Prenons un exemple plus parlant :
|
|
class Engine { public: void start(); }; class Car : private Engine { public: using Engine::start; }; |
Nous avons déclaré une classe Engine (moteur) et Car (voiture) qui en dérive de façon privée. Dans la déclaration de Car, nous indiquons, au sein d’une section publique et grâce au mot clé using, que nous utilisons la méthode start() de la classe parente. Celle-ci devient donc publique pour la classe fille et en dehors. Dans ce cas, on voit bien qu’un héritage public n’aurait aucun sens puisqu’une voiture “n’est pas” un moteur, elle “possède un moteur”. Certains se demandent peut être si une composition n’est pas plus indiquée dans ce cas et la réponse n’est pas évidente :
- En règle générale, oui, préférez la composition à l’héritage…
- … mais dans le cas que nous présentons ici, la composition est assez “forte” : une voiture ne peut toujours avoir qu’un seul moteur, et le fait de démarrer la voiture revient à démarrer le moteur.
Les cas où l’on peut légitimement accepter un héritage privé en lieu et place d’une composition restent très limités. Et personne ne vous blâmera si même dans ce cas, vous optez pour la composition. L’héritage privé est surtout une facilité du langage pour éviter au programmeur de saisir du code inutile : dans notre exemple, en utilisant une composition, on aurait obtenu quelque-chose de ce genre :
|
|
class Engine { public: void start(); }; class Car { public: void start() { m_engine.start(); } private: Engine m_engine; }; |
Pas vraiment plus difficile à comprendre, mais un peu plus long à taper. Et si ce n’était pas une mais vingt méthodes de Engine qu’il avait fallu “transporter” dans l’interface publique de Car, je vous laisse imaginer le temps perdu à saisir toutes les méthodes triviales qui ne font qu’appeler la “vraie” méthode du sous-objet. Dans tous les cas, notez qu’en t’en qu’utilisateur de la classe Car, vous ne devez jamais prendre en compte la présence d’un héritage privé dans sa définition : cet héritage est privé et relève de l’implémentation : l’auteur de la classe peut à tout moment décider de réécrire sa classe pour utiliser une composition classique, ou encore de redéfinir à la main chacune des méthodes, sans vous en notifier !
Remarque
Un lecteur assidu aura peut être remarqué une contradiction avec un de mes articles précédents : en effet, si j’ai indiqué un peu plus haut qu’il n’était pas possible de convertir un Car* en Engine* en dehors des méthodes de Car, ce n’était pas tout à fait vrai : cela est possible en C++, par l’intermédiaire d’une “conversion à la façon C”. Évidemment, si on respecte la clause énoncée précédemment de ne jamais se baser sur le détail d’implémentation que représente l’héritage privé, il ne s’agit en fait que d’un argument supplémentaire contre l’utilisation de ce type de conversion. En un mot : faites-le une fois pour vous amuser, puis plus jamais !
À propos du mot clé using
S’il est très courant de rencontrer le mot clé using lors de l’utilisation d’héritage privé, il est également possible de l’utiliser lors d’un héritage “classique” public :
|
|
class Base { public: int x() const { return m_x; } protected: void set_x(int value) { m_x = value; } private: int m_x; }; class Derived : public Base { public: using Base::set_x; }; |
Ici, nous avons augmenté la visibilité de la méthode set_x() en la rendant publique dans la classe dérivée, alors qu’elle n’était que protégée dans la classe de base. Bien que peu courante, cette syntaxe n’en demeure pas moins tout à fait correcte.
L’héritage protégé
L’héritage protégé ressemble énormément à l’héritage privé. En fait, sa seule différence est la suivante :
- Tout membre public ou protégé hérité au travers d’un héritage protégé est également accessible de façon protégée aux classes filles de la classe dérivée.
Ce qui se traduit par :
|
|
class Engine { protected: void start() {}; }; class Car : protected Engine {}; class Robot : protected Car { public: using Engine::start; }; |
Ici Robot peut accéder à la méthode protégée de Engine parce que Car hérite de Engine au travers d’un héritage protégé. On voit que si l’héritage privé peut s’avérer utile dans certains cas, l’héritage protégé lui a un intérêt beaucoup plus limité, car le fait de pouvoir accéder aux méthodes de sa classe grand-parente ne fait qu’augmenter le couplage.
Je n’ai encore jamais rencontré ou eu besoin d’un héritage protégé depuis que je développe en C++.
L’héritage virtuel
Pour expliquer en quoi consiste l’héritage virtuel, replaçons avant tout dans le contexte quelques lieux communs :
L’héritage multiple
C++ est l’un des rares langages à autoriser l’héritage multiple là où les autres langages préfèrent imposer la notion d’interfaces. La légitimité de l’une ou de l’autre de ces techniques est un sujet à part entière et sort du cadre de cet article. Si vous vous intéressez à ce débat, il existe sur l’Internet bien des discussions à ce sujet.
La minute “rebelle”
Vous avez certainement déjà entendu quelqu’un dire une chose du genre : “L’héritage multiple c’est toujours une hérésie, ça n’aurait jamais du exister ! Je n’ai jamais réussi à en faire quoi que ce soit d’utile.”
Face à ce genre de remarque simpliste, j’ai tendence à avoir la même réaction que Marshall Cline : les gens qui vous disent ça ne connaissent à priori pas votre problème ou vos besoins, et pourtant ils prétendent y répondre : comment le pourraient-ils ? Comment peuvent-ils savoir que dans votre situation, l’héritage multiple n’est pas la meilleure solution ? Si vous rencontrez ce genre de personnes, soyez prudents : le manque d’ouverture d’esprit et de réflexion fait en général de bien piètres programmeurs. Une phrase que j’aime bien citer dans cette situation est celle-ci : “Toutes les phrases qui dénoncent un principe de façon absolue et générale sont absolument et généralement fausses”. Si l’héritage multiple semble être la solution à votre problème, n’hésitez pas à l’utiliser.
Dans tous les cas, réfléchissez toujours bien à ce que vous faites : si l’héritage multiple est tant victime d’à priori négatifs, c’est qu’il est parfois difficile de comprendre son utilisation.
La démonstration par l’exemple
Pour illustrer les notions d’héritage multiple et virtuel, créons tout d’abord une hiérarchie de classes :

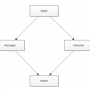
Hiérarchie de classe à héritage multiple
Comme nous le voyons ici, nous partons d’une classe Shape (“forme” en anglais), de laquelle dérivent deux classes Rectangle et Diamond (“losange” en anglais). Une quatrième classe, Square (“carré” en anglais) hérite à la fois de Rectangle et de Diamond.
Une implémentation naïve de cette hiérarchie en C++ pourrait ressembler à :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Shape { public: int identifier() const { return m_identifier; } virtual void draw() = 0; private: int m_identifier; }; class Rectangle : public Shape { public: void draw() { /* ... */ } }; class Diamond : public Shape { public: void draw() { /* ... */ } }; class Square : public Rectangle, public Diamond { public: void draw() { /* ... */ } }; |
Cela a du sens : un carré (si on s’en réfère aux lois de la géométrie) est à la fois un rectangle et un losange, et il est aussi une forme.
Cependant, ce code n’a en pratique pas la structure souhaitée :
En effet, en utilisant un héritage classique (non virtuel) Square hérite en pratique deux fois de Shape : une fois par la branche de gauche (Rectangle), et une fois par la branche de droite (Diamond). Il en résulte que chaque instance de Square possède deux instances de m_identifier. Lorsqu’on souhaite utiliser identifier() ou m_identifier dans ou en dehors de la classe Square, il faut préciser par quelle branche on passe :
- Soit en préfixant m_identifier par
Diamond ou Rectangle (“Rectangle::m_identifier“);
- soit en effectuant auparavant une conversion de
this vers Rectangle* ou Diamond* (“static_cast(this)->m_identifier“)
Ce n’est généralement pas ce qui est souhaité.
Pour résoudre ce problème, nous avons besoin de l’héritage virtuel :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Shape { public: int identifier() const { return m_identifier; } virtual void draw() = 0; private: int m_identifier; }; class Rectangle : public virtual Shape // Notez la présence de "virtual" ici { public: void draw() { /* ... */ } }; class Diamond : public virtual Shape // Notez la présence de "virtual" ici { public: void draw() { /* ... */ } }; class Square : public Rectangle, public Diamond { public: void draw() { /* ... */ } }; |
En spécifiant que Rectangle et Diamond héritent tous deux virtuellement de Shape, nous empêchons la multiple instanciation du type de base : il n’y a alors plus qu’une seule instance de m_identifier et on peut y référer directement sans avoir recours à des conversions.
Bonnes pratiques
L’utilisation de l’héritage virtuel peut se faire conjointement avec tout autre type d’héritage (privé, protégé et public), mais est habituellement rencontré principalement avec l’héritage public.
Indépendamment de l’utilisation de l’héritage virtuel, on constate assez logiquement que les classes les plus en haut de la hiérarchie devraient dans l’idéal être virtuelles pures. Si c’est le cas, cela ne signifie pas forcément qu’il faille supprimer l’héritage virtuel : outre le fait de ne pas dupliquer inutilement les instances des membres, l’héritage virtuel permet également de s’assurer que la classe de base n’a qu’une seule adresse dans les instances filles. Il est en pratique très probable que vous deviez user d’héritage virtuel lorsque vous utilisez l’héritage multiple.
Conclusion
Nous avons vu au travers des différentes sections que C++ est très complet en matière d’héritage. Élément incontournable de la programmation orientée objet moderne, c’est un principe qu’il convient de manier avec la plus grande précaution et une bonne réflexion : si l’héritage peut résoudre bien des problèmes, il n’est de loin pas la solution universelle. Que vous optiez pour l’héritage, la composition ou autre chose pour la résolution de vos problèmes, réfléchissez toujours et envisagez chacune des possibilités.
Comme toujours, n’hésitez pas à me faire part de vos remarques, questions ou corrections dans les commentaires.
Sources
Voici une série de liens en anglais qui m’ont inspiré pour la rédaction de cet article. N’hésitez pas à les consulter, ils sont extrêmement intéressants :